It should be so easy: NoSQL databases and their schemaless approach to the world. Say goodbye to tables, primary keys, foreign keys, and most importantly – Migration! Unfortunately the reality is not quite as black and white. I’ve been working with NoSQL databases such as Elasticsearch, RavenDB, MongoDB and CouchDB more or less constantly over the last five years. The past year more intense during the development of my cloud logging project elmah.io. I’ve not yet come across a NoSQL database which does not need some sort of data migration.
In this blog post I will dig down into data migrations in Elasticsearch, which is the great search engine we use on elmah.io. The examples are written in C# with the official Elasticsearch client NEST, but the procedure will be the same with other programming languages.
Imagine a relational database where you need to change the zipcode column from an int to a string. You typically write a migration script and execute it against your database either manually or through a migration tool like DbUp. The script handles the data type change, but you are also forced to handle the data change of any existing rows in the table. You probably know the process.
In Elasticsearch, you can choose between two different solutions when you need to make schema changes:
- Leave it to Elasticsearch to evolve the schema.
- Do a PutMapping call on Elasticsearch with an updated schema.
In practice I always choose options 2, because it gives me full control over how and when changes are happening. Another thing is, that Elasticsearch chooses data types and analyzers for new fields itself, which is not always what you wanted.
The Elasticsearch blog has an excellent solution for versioning indexes, which I will use as a foundation in the following C# examples. Briefly, this consists of appending a version number to your index name, and then create new versions of the index when changes should be made that require indexing. In order not to have to release a new version of your software, designating a new active index, you create an alias (typically index name without the version number). In this case the alias will always identify the active index. For a detailed description of the approach I recommend you to read the content on the link above.
Let’s start by creating a new index with a schema:
var connectionSettings = new ConnectionSettings(new Uri("http://localhost:9200/"));
connectionSettings.SetDefaultIndex("customers");
var elasticClient = new ElasticClient(connectionSettings);
elasticClient.CreateIndex("customers-v1");
elasticClient.Alias(x => x.Add(a => a.Alias("customers").Index("customers-v1")));
elasticClient.Map<Customer>(d =>
d.Properties(p => p.Number(n => n.Name(name => name.Zipcode).Index(NonStringIndexOption.not_analyzed))));
In the example I create a new index called customers-v1 and add a mapping (schema) for the C# type Customer with a single field Zipcode. The result is shown in the following screenshot:
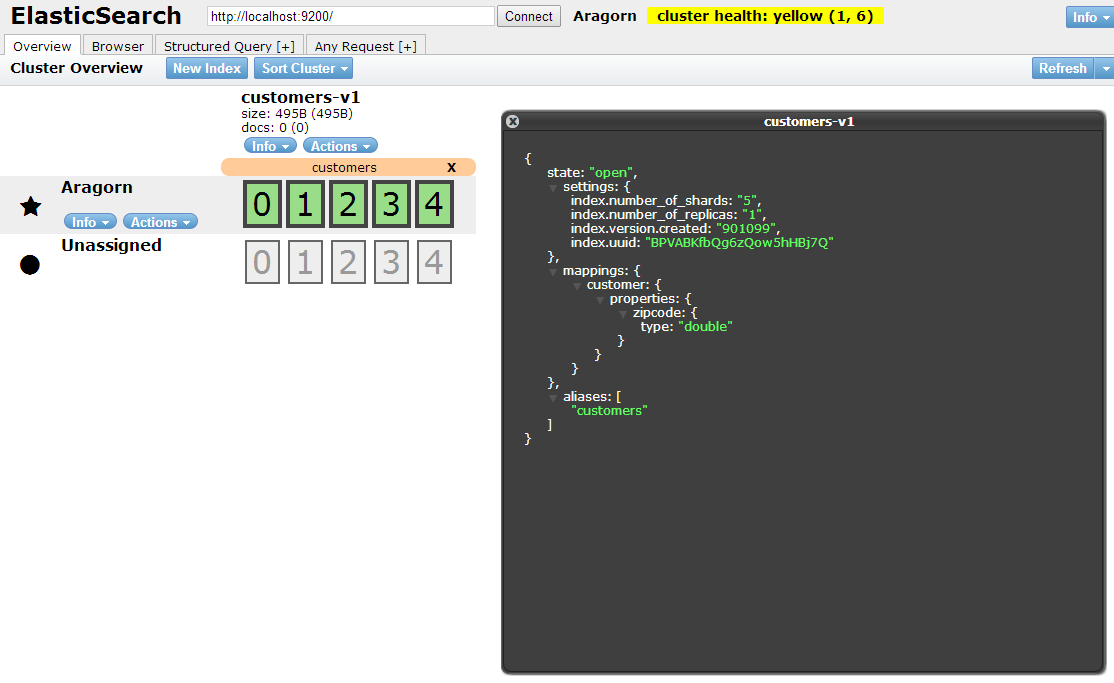
Then I insert a Customer document:
elasticClient.Index(new Customer { Zipcode = 8000 });
Now we imagine that I need to change the type of Zipcode from Number to String and simultaneously migrate existing documents. I can not directly change the type of an existing field in Elasticsearch why I write a migration using the Reindex method in NEST:
var reindex =
elasticClient.Reindex<Customer>(r =>
r.FromIndex("customers-v1")
.ToIndex("customers-v2")
.Query(q => q.MatchAll())
.Scroll("10s")
.CreateIndex(i =>
i.AddMapping<Customer>(m =>
m.Properties(p =>
p.String(n => n.Name(name => name.Zipcode).Index(FieldIndexOption.not_analyzed))))));
var o = new ReindexObserver<Customer>(onError: e => { });
reindex.Subscribe(o);
The Reindex method needs from and to index names, as well a what documents to reindex. In this case I tell it to match all documents. As part of the Reindex call, the v2 index is automatically created and a PutMapping call is made. This corresponds to the CreateIndex and Map methods called in the previous example.
Last but not least, we change the alias to point to the new index:
elasticClient.DeleteIndex(d => d.Index("customers-v1"));
elasticClient.Alias(x => x.Add(a => a.Alias("customers").Index("customers-v2")));
The first line deletes the old index, which also deletes the alias. Then I re-create the alias and set it to point to the customers-v2 index.
When put together it becomes clear, that data migration is far from a closed chapter in NoSQL databases like Elasticsearch. This is not a bad thing and as it turns out, migrations is a lot easier since many changes can be made without executing scripts against the database. Furthermore, there is great build-in support for re-indexing, making it easy for those situations where you need to rebuild an index.
The complete code sample can be found at https://gist.github.com/ThomasArdal/1f69720da208f1863ae7.