This is the second and final post in the series Evaluating Azure DocumentDB. Where Part 1 focused around the concepts in DocumentDB, I’ll explore some actual code in this post.
Inserting documents
Before we dig into the code, there’s a couple of terms in DocumentDB that you should know. Much like other NoSQL offerings, you have the concept of databases and collections. A database maps pretty much 1:1 with a database in SQL Server. I have seen collections mapped to SQL Server tables and though collections can be used this way, it’s not recommended to do so. A collection in DocumentDB is more of a logical unit for storing one or more types of documents.
With the basics in place, let’s insert a new document in DocumentDB:
var documentClient = new DocumentClient(Url, Key);
await documentClient.CreateDocumentAsync(
UriFactory.CreateDocumentCollectionUri("test", "documents"),
new UserDocument
{
Id = "User1",
Username = "ThomasArdal",
Firstname = "Thomas",
Lastname = "Ardal",
});
To start using DocumentDB, I create a new DocumentClient, which acts as the main entry point for communicating with the server. Url and Key is copied from the Azure Portal.
In the code sample, I create a new UserDocument, which is a simple POCO defined elsewhere in the project. The only weird looking part here (at least to my eyes), is the UriFactory.CreateDocumentCollectionUri call. This is the way to tell DocumentDB which collection to put the new document into. I don’t really like to specify this on every request, since it’s simply an Uri created from magic strings. It’s possible to query collections, but unfortunately collections don’t allow for creating or querying documents. I would have preferred to be able to inject collection objects through IoC.
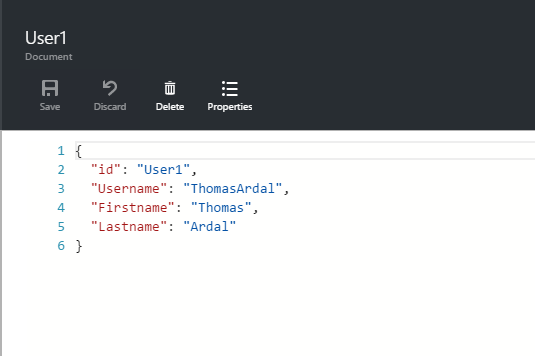
There’s a nice management tool for DocumentDB, located on the Azure Portal. Going there shows us the new document which is indeed just JSON:
Querying
DocumentDB supports SQL like syntax for querying documents. In fact Microsoft always seems to mention all of the “benefits” of using SQL rather than an NoSQL query language known from databases like CouchDB and Elasticsearch. I don’t really agree on the fact that we need SQL for querying a NoSQL datastore, but luckily, the DocumentDB .NET client implements a LINQ provider. The provider still seems limited in the amount of methods available, but I assume that this will improve over time.
Let’s insert a new document to have some different document types to query:
await documentClient.CreateDocumentAsync(
UriFactory.CreateDocumentCollectionUri("test", "documents"),
new OrderDocument
{
Id = "Order1",
Amount = 42,
Created = DateTime.UtcNow,
CreatedBy = "User1",
});
To query all orders created by User1:
var orderDocuments = documentClient.CreateDocumentQuery<OrderDocument>(
UriFactory.CreateDocumentCollectionUri("test", "documents"))
.Where(order => order.CreatedBy == "User1");
foreach (var order in orderDocuments)
{
Console.WriteLine("Order on {0} by {1}", order.Amount, order.CreatedBy);
}
The output shows the expected Order1:
Order on 42 by User1
Remember in the first post, where I said that this is truly just a JSON store with some search capabilities on top? To prove the point, we’ll insert a new UserDocument:
documentClient.CreateDocumentAsync(
UriFactory.CreateDocumentCollectionUri("test", "documents"),
new UserDocument
{
Id = "User2",
Username = "ThomasArdal",
Firstname = "Thomas",
Lastname = "Ardal",
CreatedBy = "User1",
}).Wait();
For the example, I’ve extended UserDocument with a new property named CreatedBy.
If we try the query again, we now get:
Order on 42 by User1
Order on 0 by User
If you’re thinking WTF I don’t blame you. We searched for OrderDocuments with a CreatedBy value of User1. Unfortunately the generic type on CreateDocumentQuery only acts as info to tell the DocumentDB client library how to deserialize the response. This means that the query finds both the OrderDocument and UserDocument with the value User1 in the CreatedBy field. The .NET client then tries to map the returned UserDocument to a OrderDocument.
To fix this, you could add a Type property to all of your documents and include this in all queries. It’s a bit shame that this process isn’t automated somehow. I can understand why it’s build the way it is, being a 100 % schemaless datastore. But with generics in C#, this could have been improved by having meta data fields or similar on all documents.
That’s it for now. I may want to write additional posts about more complex query scenarios and/or data migration.