I talk to a range of customers during my work as an external consultant. It never ceases to amaze me how few who have actually considered setting up retention on their data. I know that storage is cheap these days, but most data stores handle large amounts of data poorly, unless scaled to an enterprise setup, which may not even be needed.
In this post I will focus around setting up retention on Elasticsearch indices. Elasticsearch is able to handle a lot of documents. It will cost you storage obviously, but also a lot of RAM and CPU. I bet you use Elasticsearch for logging data through Serilog, log4net, logstash or similar. Ask yourself if you actually need years and years of logging data. If not, Elastic provides a nice little tool called Curator for cleaning up indices.
For the demo here, I assume that you have a bunch of Elasticsearch data separated into an index per day:

This behavior is supported by Serilog and other logging frameworks. It’s generally a good rule of thumb to split logging data into separate indices, since Elasticsearch don’t need to search through all data when specifying a date range. Also having logging data split into logical parts, makes it easier to clean up data that we no longer need.
To start using Curator, you need to install Python. I’ve had best luck using 2.7, but newer versions should do as well.
When installed, Curator is easily installed through Pip (package manager for Python):
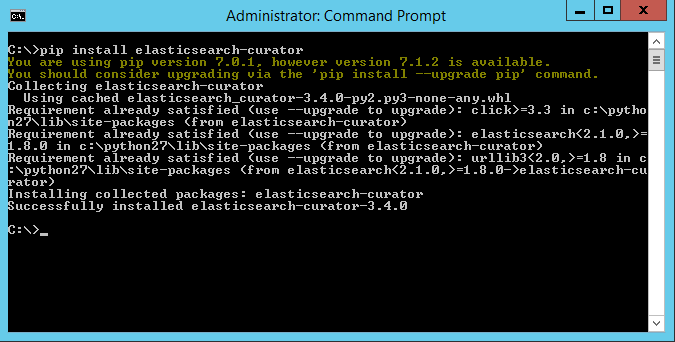
That’s it. You now have Curator in your path as a Windows executable. To delete logstash indices older than, let’s say 7 days, run Curator with a few options:
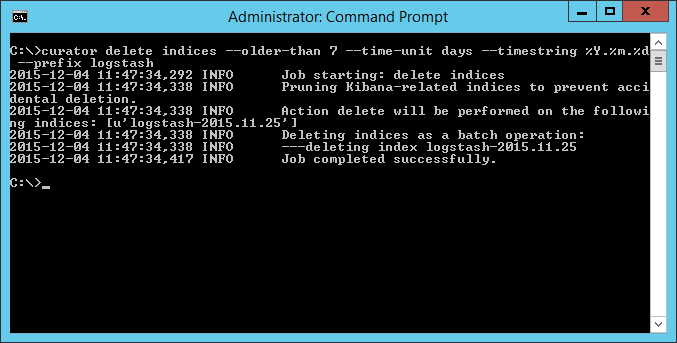
In the example above, the index from 2015.11.25 where successfully deleted, since it is more than 7 days old from the day of writing this.
To avoid having to run this manually, you can setup a Scheduled Task: